Driving on Registers
Ellington Kirby* Alexandre Boulch* Yihong Xu* Yuan Yin Gilles Puy Eloi Zablocki Andrei Bursuc Spyros Gidaris Renaud Marlet Florent Bartoccioni Anh-Quan Cao Nermin Samet Tuan-Hung VU Matthieu Cord
Computer Vision and Pattern Recognition (CVPR), 2026
Abstract
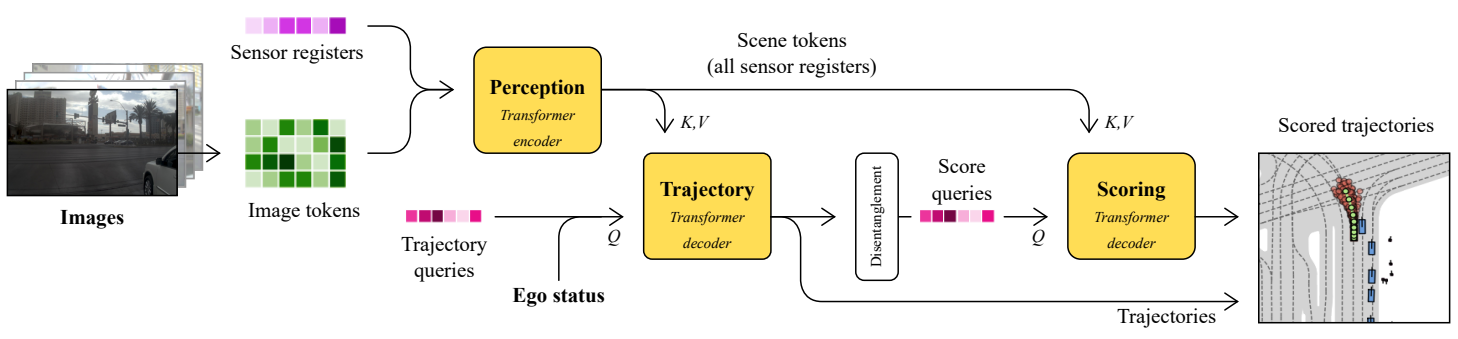
We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving.