Improving Multimodal Distillation for 3D Semantic Segmentation under Domain Shift
Björn Michele Alexandre Boulch Gilles Puy Tuan-Hung Vu Renaud Marlet Nicolas Courty
British Machine Vision Conference (BMVC), 2025
Abstract
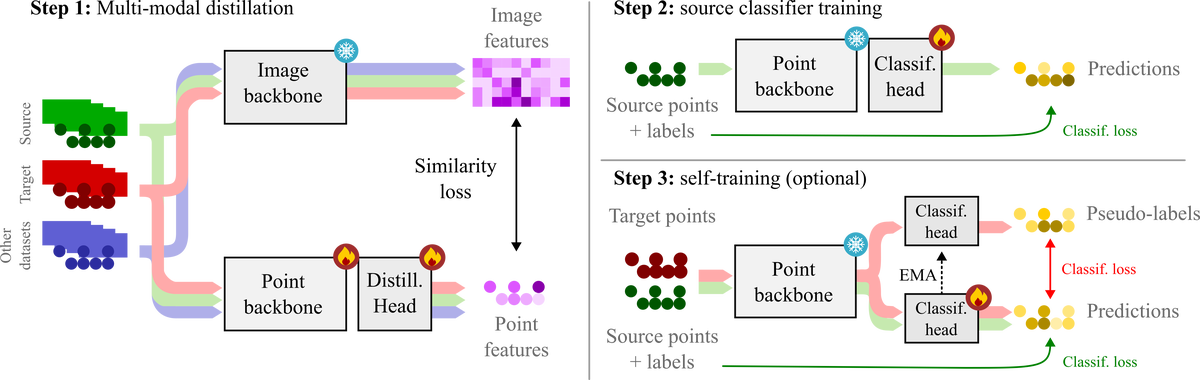
Semantic segmentation networks trained under full supervision for one type of lidar fail to generalize to unseen lidars without intervention. To reduce the performance gap under domain shifts, a recent trend is to leverage vision foundation models (VFMs) providing robust features across domains. In this work, we conduct an exhaustive study to identify recipes for exploiting VFMs in unsupervised domain adaptation for semantic segmentation of lidar point clouds. Building upon unsupervised image-to-lidar knowledge distillation, our study reveals that: (1) the architecture of the lidar backbone is key to maximize the generalization performance on a target domain; (2) it is possible to pretrain a single backbone once and for all, and use it to address many domain shifts; (3) best results are obtained by keeping the pretrained backbone frozen and training an MLP head for semantic segmentation. The resulting pipeline achieves state-of-the-art results in four widely-recognized and challenging settings.
Citation
@inproceedings{michele2025muddos,
title={Improving Multimodal Distillation for 3D Semantic Segmentation under Domain Shift},
author={Michele, Bj{\"o}rn and Boulch, Alexandre and Vu, Tuan-Hung and Puy, Gilles and Marlet, Renaud and Courty, Nicolas},
booktitle={Proceedings of the British Machine Vision Conference (BMVC)},
year={2025}
}